Updated May 21, 2026
AIF-C01 v1.1 — Study Notes
Plain-language guide to passing the AWS AI Practitioner exam, organized by exam domain. Every section is written like you've never touched AWS before — then bridges into the precise vocabulary the exam tests.
The Five Domains
The exam is weighted by domain. Domain 3 (28%) is by far the most important — you cannot pass while bombing it.
Domain 1
Fundamentals of AI and ML
20%What AI/ML/deep learning/GenAI actually mean, learning types, data types, the ML lifecycle, when AI is the wrong tool.
Domain 2
Fundamentals of Generative AI
24%Foundation models, tokens, embeddings, the FM lifecycle, AWS GenAI services, capabilities and hard limits.
Domain 3
Applications of Foundation Models
28%The big one. Prompt engineering, RAG, fine-tuning vs. continued pre-training vs. distillation, agents, evaluation.
Domain 4
Guidelines for Responsible AI
14%Bias, fairness, transparency, explainability, model cards, guardrails, human-in-the-loop.
Domain 5
Security, Compliance, Governance
14%IAM, KMS, the Generative AI Security Scoping Matrix, shared responsibility model, audit and compliance services.
Cross-Domain Gotchas
Trap categories that wreck candidates regardless of which domain a question is in.
Service-confusion pairs that always trick people
- Bedrock vs SageMaker AI — Bedrock = consume FMs via API. SageMaker AI = build, train, deploy your own models end-to-end.
- Amazon Q Business vs Amazon Q Developer — Q Business = enterprise chatbot grounded in your company data. Q Developer = code assistant in your IDE/CLI.
- Kendra vs Bedrock Knowledge Bases — Kendra = enterprise search returning ranked docs. Knowledge Bases = managed RAG returning generated answers.
- Rekognition vs Textract — Rekognition = images/video (faces, objects, moderation). Textract = printed/handwritten text in images/PDFs.
- Comprehend vs Transcribe vs Translate — Comprehend = analyze text. Transcribe = audio→text. Translate = text→other language.
- SageMaker Clarify vs Model Monitor vs Model Cards — Clarify = bias and explainability. Model Monitor = data/concept drift in production. Model Cards = documentation/lineage for governance.
Wording traps in scenario questions
- "Most cost-effective" with low query volume → on-demand token pricing, NOT provisioned throughput.
- "Steady, predictable, high-volume traffic" → provisioned throughput.
- "Without retraining the model" → RAG, prompt engineering, or in-context learning. Never fine-tuning.
- "Reduce hallucinations on internal company data" → RAG (Knowledge Bases). Not fine-tuning.
- "Make a smaller, faster model from a larger one" → model distillation.
- "Adapt model to specialized vocabulary, no labeled data" → continued pre-training.
- "Detect bias before deployment" → SageMaker Clarify.
- "Detect drift after deployment" → SageMaker Model Monitor.
- "Block specific topics or PII in model responses" → Bedrock Guardrails.
Exam mechanics that punish unprepared candidates
- Multi-response questions (pick 2 or pick 3) have no partial credit.
- Ordering questions exist (FM lifecycle, ML pipeline) — you must drag steps into the correct order.
- Matching questions exist — pair services to use cases.
- Time budget: 90 min ÷ 65 questions ≈ 83 seconds each. Flag and skip anything that takes more than 2 minutes.
Diagrams
Visual references for key concepts.
AI / ML / DL / GenAI Hierarchy
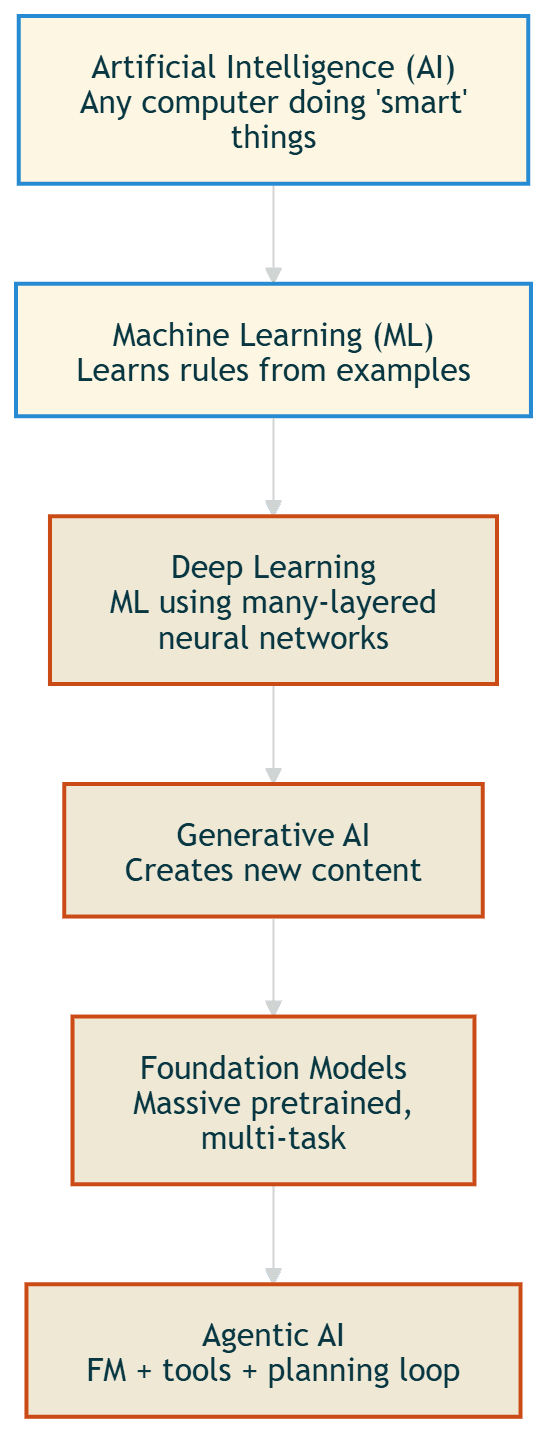
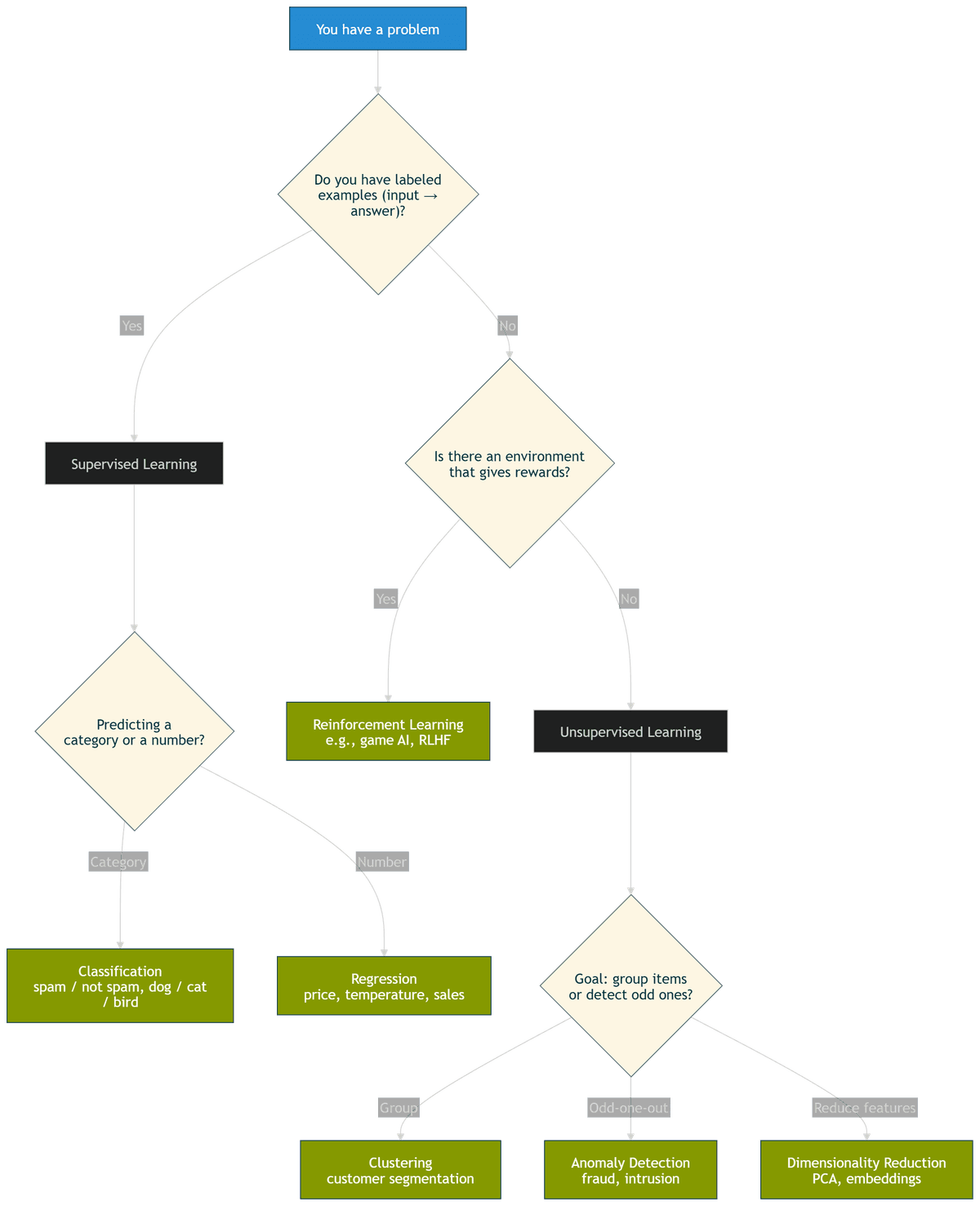
Supervised / Unsupervised / Reinforcement
External Resources
Official AWS
How to Use This Study Hub
- Click a domain card above to open its full study notes.
- Each page has collapsible sections — open them as you study, leave them closed for review.
- Quiz cards have a "Show answer" button — try the question first, then reveal.
- Flashcards flip when you click them — use for vocab drilling.